

- This event has passed.
Anonymity of Multi-hop Neighborhoods in Social Networks
20 July 2022 , 19:20 – 20:20 CEST
Conference poster presentation by Rachel de Jong at Harper Center of the Booth School of Business at the University of Chicago.
Authors: Rachel de Jong, Mark van der Loo and Frank Takes
Introduction & Goal. Sharing large-scale social network datasets is advantageous for the development of computational social science, since studying and replicating findings on such datasets is key to understanding and modeling various social phenomena [1, 2]. Following the principles of widely implemented privacy laws such as GDPR, such datasets need to be anonymous, which means that people should not be identifiable by someone with a realistic amount of background knowledge. This work focuses on a method to assess this so-called risk of disclosure, by measuring the anonymity of individuals in networks based on their structural position within the network.
Previous work has focussed on measuring anonymity using only the direct surroundings of a node [3]. However, in [4] it is shown that when a possible attacker has information about a larger neighborhood beyond these direct surroundings, this could drastically decrease the anonymity of the individual. Therefore, in this work, we present a novel approach that extends these two earlier works into a parametrized measure that can serve as a lower bound for the expected anonymity at different levels of knowledge of the attacker. On both modeled and real-world social network data, we demonstrate that if an attacker has perfect information about what we call multi-hop neighborhoods, the anonymity of individuals in the social network is severely compromised. This has serious implications for any social science researcher sharing social network data with other parties.
Approach. We measure the anonymity by partitioning the set of nodes of a given social network into equivalence classes. We define equivalence by using the measure of d–k-anonymity, where two nodes are d-equivalent if 1) their respective d-hop neighborhoods (i.e., neighborhoods up to distance d of the node) are isomorphic, and 2) there is an isomorphism mapping the two compared nodes onto each other. Next, following [3], we define a node as unique if it has no equivalent nodes in the network.
To understand anonymity of individuals in real-world networks, we measure structural anonymity in various known graph models (Erdős–Rényi (ER) and Watts Strogatz (WS)) and a range of empirical network datasets. We investigate anonymity for increasingly larger hop neighborhoods, and therewith different attacker knowledge scenarios. This improves upon [3] because we allow for larger-hop neighborhoods, and upon [4] because we assume perfect information about connectivity of individuals up to a certain distance.
Results. Figure 1 shows the fraction of unique nodes as a function of the number of nodes n and the average degree. Blue indicates a small fraction of unique nodes, thus, high anonymity, and red indicates a large fraction of unique nodes, thus, low anonymity. In the case where d=1, so in the leftmost column of Figure 1, our work reproduces precisely the findings in [3]. However, most importantly, for larger d-hop neighborhoods, shown in the middle and rightmost columns of Figure 1, we see that the uniqueness landscape changes completely. The number of unique nodes, and its dependence on n and the average degree, both change drastically. This holds for both models: the fraction of unique nodes becomes high for networks with lower average degrees, and increasing the network size has less effect on the fraction of unique nodes than for d=1. We conclude that increasing the distance therefore radically decreases the overall anonymity of nodes in the network.
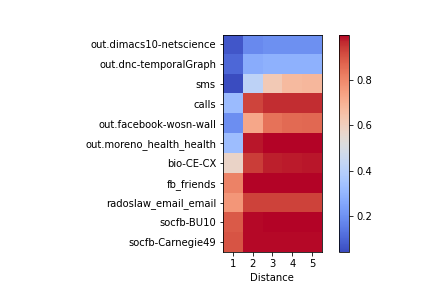
In Figure 2, we summarize our findings for various empirical networks with sizes ranging from 167 to 19.7K nodes. For 10 different real-world networks, we observe behavior in three categories: 1) high anonymity at d ≥ 1, 2) high anonymity at d=1, low anonymity at d ≥ 2 and 3) low anonymity at d=1. Despite currently being publicly available for research, for most network datasets a large fraction of nodes is uniquely identifiable when information about the 1-hop neighborhood is known. When information about 2-hop neighborhoods is known, this fraction increases drastically; more entities represented in the network can be uniquely identified and are thus not anonymous.
Conclusions. Our results show that if an attacker has perfect information about multi-hop neighborhoods, even just at distance two, then this can drastically reduce the anonymity of nodes in networks, as observed for the network models and the empirical networks analyzed in our experiments. Since it is realistic for an attacker to obtain some (but not always all) information about larger-hop neighborhoods, one cannot dismiss the de-anonymizing effects of network structure surrounding a node for d ≥ 2. In future work, we will explore the effect of possible incomplete knowledge of neighborhood structure. Moreover, we will investigate how by using small perturbations, networks can in fact be made fully d-k-anonymous.
References
- Lazer, D., et al. (2020). Computational social science: Obstacles and opportunities. Science 369.6507: 1060-1062.
- van der Laan, J. and E., de Jonge (2017). Producing official statistics from network data. In Proceedings of the 6th International Conference on Complex Networks and Their Applications, pp. 288-289.
- Romanini, D., Lehmann, S. & Kivelä, M. (2021). Privacy and uniqueness of neighborhoods in social networks. Scientific Reports 11: 20104.
- Hay, M., Miklau G., Jensen, D., Towsley D., Weis P. (2008). Resisting Structural Reidentification in Anonymized Social Networks. In Proceedings of the VLDB Endowment, 1.1, pp. 102-114.
- Jérôme Kunegis (2013). KONECT – The Koblenz Network Collection. In Proceedings of the International Conference on World Wide Web Companion, pp. 1343–1350.
- Ryan A. Rossi and Nesreen K. Ahmed. (2015). The Network Data Repository with Interactive Graph Analytics and Visualization. In AAAI Conference on Artificial Intelligence, pp. 4292-4293.
- Sapiezynski, P., Stopczynski, A., Lassen, D. D. & Lehmann, S. (2019). Interaction data from the Copenhagen networks study. Scientific Data 6.1: 315.
  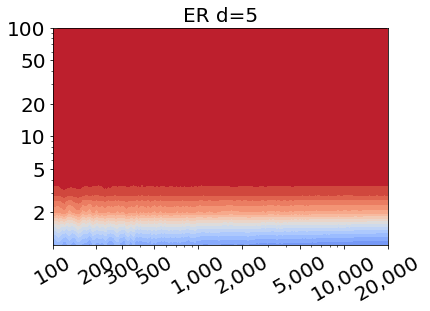   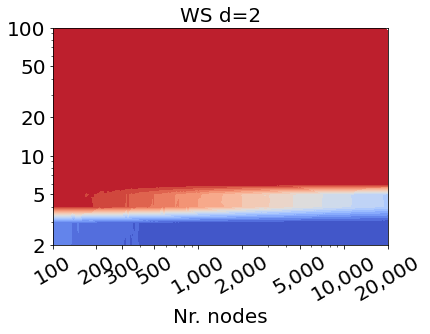  |
| Figure 1. Fraction of unique nodes in artificial network models. Top: Erdős–Rényi (ER), bottom: Watts Strogatz (WS). Size: 100-20,000 nodes. Average degree 2-100. Distance d from left to right: 1, 2, 5. |
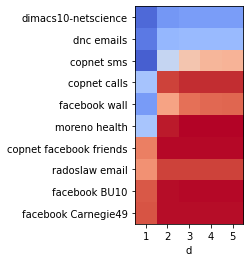 |
| Figure 2. Fraction of unique nodes in real-world networks [5, 6, 7], for different values of distance d. |